API Documentation
Overview
The Text to JSON API provides a convenient interface for extracting structured data from unstructured text using large language models (LLMs). You can send text, images, or PDFs to the API and receive JSON data in the shape of your schema.
Defining a Schema
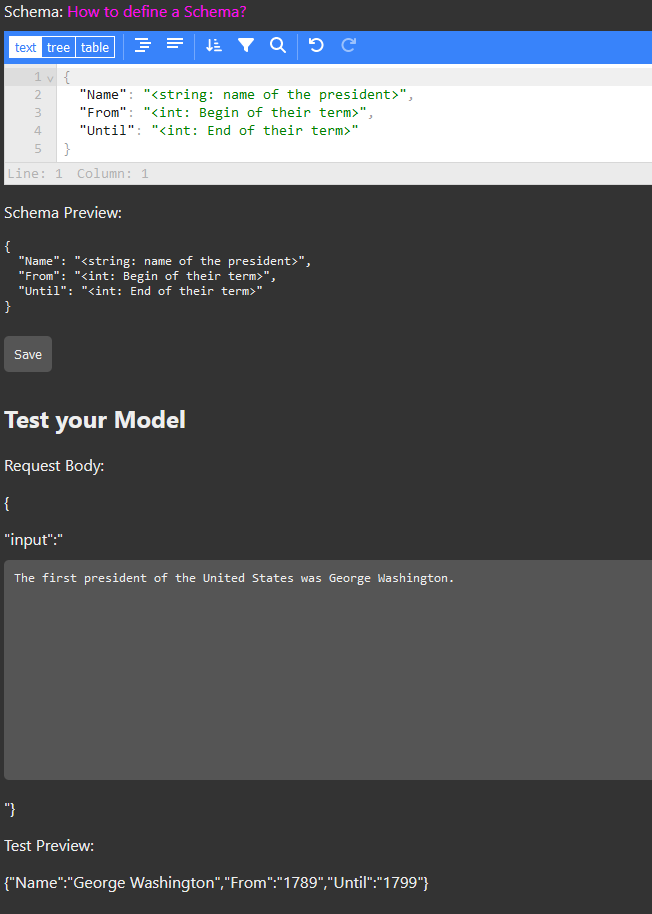
To let the llm know what data you want in your JSON structure. The schema is a JSON object of the same shape you want the output to have. The value of every property is a string in angle brackets with a type and a description. For example:
{
"customer": {
"company_name": "<string: The name of the company>",
"vat_id": "<string: The VAT (Value Added Tax) identification number of the company>",
"contact": {
"first_name": "<string: The first name of the contact person>",
"last_name": "<string: The last name of the contact person>",
"email": "<string: The email address of the contact person>"
},
"address": {
"street": "<string: The street address of the company>",
"town": "<string: The town or city where the company is located>",
"zip_code": "<string: The postal code of the company's location>"
}
}
}
You can specify data types and text-to-json will automatically enforce
those data types in the response. Supported datatypes are:
- number: A general numeric data type to handle both integers and floating point numbers.
- string: Returns the value as a string.
- boolean: Represents truth values. Can for example be used to check if something occurs in the input.
- bool: Shorthand for boolean.
- date: A date represented as a ISO 8601 string (e.g. "2022-01-01T00:00:00.000Z").
 It is recommended to add fallback values and to follow other best practices to increase accuracy of results. Fields not present in the text will
be omitted automatically unless a fallback value is specified. An example
of implementing fallback values is shown below:
It is recommended to add fallback values and to follow other best practices to increase accuracy of results. Fields not present in the text will
be omitted automatically unless a fallback value is specified. An example
of implementing fallback values is shown below:
[
{
"name": "<string: Name of the ingredient>",
"amount": "<float: Amount of the ingredient if the amount is not given use 1>",
"unit": "<string: Unit of the ingredient if the unit is given or 'piece' if not mentioned e.g. \"g\",\"kg,\"piece\",\"lb\",\"tsp\",\"tbsp\",\"cup\",\"fl\",\"oz\",\"ml\">"
}
]
Querying with the Text API
To query the model with your own input, you'll need to send a POST request to the `/api/v1/infer` endpoint along with specific query parameters.
POST /api/v1/infer
This endpoint allows you to input text to the model and receive the model's output in response.
Request URL
This is found on the model's page on the website after saving it.https://text-to-json.com/api/v1/infer?uuid=<YOUR_MODEL_UUID>&apiToken=<YOUR_API_TOKEN>
Query Parameters
- apiToken: This is your API token, which authorizes your requests to the API. Replace <YOUR_API_TOKEN> with your actual API token.
- uuid (optional): This is the unique identifier for your specific schema that can be found on the model page. You can also specify the schema with the body parameter schema instead.
Body
The body parameters are:
- input: The text you want to process.
- schema (optional): The schema you want to the response to be. When uuid is set, the schema parameter is ignored.
- timezone (optional): The timezone identifier used when parsing dates into ISO 8601 format. (default: europe/vienna)
- languageModel (optional):
The LLM used for inference. They are formatted as <provider/model>.
For example openai with gpt-3.5-turbo would be specified
as "openai/gpt-3.5-turbo". There are currently 4 providers
with different models:
- openai
- gpt-3.5-turbo
- gpt-4
- azure
- gpt-35-turbo
- vertex
- text-bison@001
let res = await fetch(URL, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ input: 'I am Franklin D. Roosevelt. I was the 32nd president of the United States.', schema: { 'Name': '<string: name of the president>', 'From': '<date: the beginning of his term>', 'Until': '<date: the end of his term>', }, languageModel: 'openai/gpt-3.5-turbo', timezone: 'europe/vienna' }) }).then(r => r.json());
Response
The response will be a JSON object structured as defined in the schema. The structure of this JSON object can deviate from your schema depending on the input and is not guaranteed to be correct.
Querying with the Document API
Text-to-JSON also supports a document API. This API allows you to just provide a document as PDF or image and get the extracted data in JSON format. The document API uses a custom OCR toolchain to extract multiple text options from the provided documents and queries the language model with the extracted text.
POST /api/v1/inferDocument
This endpoint allows you to input a document to the model and receive the model's output in response.
Query Parameters
- apiToken: This is your API token, which authorizes your requests to the API.
- uuid (optional): The unique identifier for your specific schema that can be found on the model page. Can be omitted if the body parameter "schema" is set.
Request Body
- schema (optional): The schema you want the response to be. When uuid is set, the schema parameter will be ignored.
- uuid (optional): The uuid of the schema you want to use. Can be omitted if the body parameter "schema" is set.
- data: The dataurl encoded file (PDF, JPEG, or PNG).
- mimetype: The mimetype of the file. Supported mimetypes are "application/pdf", "image/jpeg", and "image/png".
- parsingsteps (optional): An array
of languagemodel inference steps:
- name: The name of the languagemodel equivalent to the languageModel parameter in the infer API.
- maxcount: The maximum number of inferences using the model.
- type: The formatting mode
of the text to give to the language model. Can be "raw",
"padded", or "image". Default is "raw".
"raw" uses the OCR results without attempting to preserve the layout of the text. "raw" is better if there is little semantics in how a page is structured.
"padded" attempts to recreate the text layout of the document. "padded" can be useful if the position of text is semantically important such as the position of addresses in a letter.
"image" can only be used with multimodal models (such as "vertex/gemini-1.0-pro-vision-001"). Choosing "image" will change the semantics of maxcount. In this case, maxcount = 1 will use the raw PDF/image, maxcount = 2 will additionally use the cropped image if available. Using "image" mode will bypass the ocr pipeline if it is not needed to complete the task reducing inference time.
Tip: chose "image" as the first parsing step and add other parsing steps that use "raw" or "padded" to get a fast response if the multimodal model can handle the task while maintaining output reliability by failing over to the ocr pipeline.
[ { "name": "openai/gpt-3.5-turbo", "maxcount": 3, "type": "padded" }, { "name": "openai/gpt-3.5-turbo", "maxcount": 3, "type": "raw" } ] - timezone (optional): The timezone identifier used when parsing dates into ISO 8601 format. (default: europe/vienna)
- returnprobabilities (optional): If set to true, every property in the response will contain
an array of objects of the format
- value: The extracted value.
- probability: A float between 0 and 1 representing the probability of the extracted value.
[ { "value": "the extracted value", "probability": 0.9 }, ... ]
Returns
The response will be a JSON object of the format:
- id: The uuid of the document extraction request.
{
id: "b269263d-7276-46e3-bb52-85dbde6fcd35"
}
The id can be used to query the status of the document extraction
using the /api/v1/document endpoint.
GET /api/v1/document
This endpoint allows you to query the status of the document extraction and get the extracted data.
Query Parameters
- apiToken: This is your API token, which authorizes your requests to the API.
- id: The id of the document extraction request.
Returns
The response will be a JSON object containing the fields:
- result: The extracted data.
- id: The id of the document extraction request.
- user: The user who made the request.
- token: The token used for the request.
- status: The status of the request. Can be "pending", "processing", "finished", or "failed".
- retrycount: The number of times the request has been retried. Requests that fail for some reason will attempt parsing again up to 3 times.
- started: The time the request started processing.
- finished: The time the request finished processing.
- error: The error message if the request failed.
- parsingsteps: The parsing steps used for the document extraction.
- schema: The schema used for the document extraction.
- timezone: The timezone used for the document extraction.
- returnprobabilities: Whether the response contains probabilities. If set to true, every property of the result object will contain an array of objects of the format {"value": "the extracted value", "probability": 0.9} where value is the extracted value and probability is a float between 0 and 1.
{
"result": {
"name": "John Doe",
"date_of_birth": "1990-01-01",
"address": "1234 Main St, Springfield, IL 62701",
"license_number": "1234567890",
"license_types": "A, B, C"
},
"id": "b269263d-7276-46e3-bb52-85dbde6fcd35",
"user": "e2309358-bd33-44e9-a98d-b27c44b8aeaa",
"token": "61838840-7595-40d3-bc57-d38da00a929a",
"status": "finished",
"retrycount": 0,
"started": "2024-02-28T10:27:17.971Z",
"finished": "2024-02-28T10:29:17.971Z",
"error": null,
"parsingsteps": [
{
"name": "gpt-3.5-turbo",
"maxcount": 3,
"type": "raw"
},
{
"name": "gpt-3.5-turbo",
"maxcount": 3,
"type": "padded"
}
],
"schema": {
"surname": "<string: the surname of the licensee (1)>",
"firstname": "<string: the first name of the licensee (2)>",
"date_of_birth": "<date: the date of birth of the licensee (3)>",
"date_issued": "<date: the date the driver's license was issued (4a)>",
"date_expiry": "<date: the date the driver's license expires (4b)>",
"issuer": "<string: the issuing authority (4c)>",
"license_number": "<string: the ID of the license (5)>",
"license_types": "<string: the types of licenses (9)>"
},
"timezone": null,
"returnprobabilities": false
}
GET /api/v1/documentFile
This endpoint allows you to download the original document uploaded as well as a cropped version if the document was an image. The cropped image will contain the area of the image containing the document.
Query Parameters
- apiToken: This is your API token, which authorizes your requests to the API.
- id: The id of the document extraction request.
- type: The type of file to download. Can be "original" or "cropped".
Returns
The response will be a file of the specified type.
Best Practices for Inferencing
The descriptions in the schema are important. Here are some best practices to keep in mind when using the Text to JSON API.
- Fallback values:
If you want to ensure that your model returns a value for
a specific field, you can add a fallback value to the schema.
This will ensure that the model returns a value for that
field even if it is not found in the input text. An example
of this is shown below:
[ { "name": "<string: Name of the ingredient>", "amount": "<float: Amount of the ingredient if the amount is not given use 1>", "unit": "<string: Unit of the ingredient if the unit is given or 'piece' if not mentioned e.g. \"g\",\"kg,\"piece\",\"lb\",\"tsp\",\"tbsp\",\"cup\",\"fl\",\"oz\",\"ml\">" } ] - Clarity:
Specify clearly what value a field should be set to. For
example, when parsing a letter write
{ "sender_address":"<string: address of the sender of the letter>"}{ "address":"<string: address>"} - Structure:
It is often helpful structure your data into its component
parts.
{ "street": "<string:street and building number of the sender>" "town": "<string:town of the sender>" "zip_code": "<string:zip code of the sender>" }{ "address": "<string:sender address in order street, town, zip code>" } - Typing:
Adding the intended return type to the description part of
the schema will help the model to return the correct type.
See datatypes for a list of supported
types. For example, if you want the model to return a date,
you can specify
{ "Property1":"<date:description of Property1>" }{ "Property1":"<description of Property1>" } - Referring to inputs: If you want to refer to the input string, it is most likely to succeed if you refer to it as "document".
Client Libraries
We provide client libraries to make it easier to interact with the Text to JSON API.
If you have any questions or need help with the API, feel free to email!